정확도(Accuracy)
실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
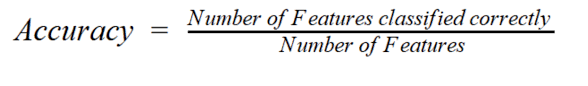
전체 예측 데이터 건수에서 예측 결과가 동일한 데이터 건수를 계산한 값이다. 불균형한 레이블 분포에서는 잘못된 예측이라도 높은 정확도가 나올 수 있기 때문에 정확도를 평과 지표로 사용할 때는 신중해야 한다. 이러한 한계점을 극복하기 위해 다양한 분류 지표를 함께 활용해야 한다.
오차행렬(Confusion Matrix)
학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고(confused) 있는지 확인하는 지표

TN : 예측값을 Negative 값 0으로 예측했고 실제 값 역시 Negative 값 0
FP : 예측값을 Positive 값 1로 예측했는데 실제 값은 Negative 값 0
FN : 예측값을 Negative 값 0으로 예측했는데 실제 값은 Positive 값 1
TP : 예측값을 Positive 값 1로 예측했는데 실제 값 역시 Positive 값 1
위의 정확도(Accuracy)를 오차행렬로 나타내면 이렇게 나타낼 수 있다.

정밀도(Precision)와 재현율(Recall)
정밀도(Precision) : 예측을 Positive로 한 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율
재현율(Recall) : 실제 값이 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율

정밀도는 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 큰 문제가 발생하는 경우 평가 지표로 활용한다. 스팸메일을 판단하는 모델일 때 Negative인 일반 메일을 Positive인 스팸 메일로 분류하는 경우가 해당한다.
재현율은 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단할 때 문제가 생기는 경우 평가 지표로 활용한다. 금융 사기 적발 모델일 때 실제 금융거래 사기인 Positive 건을 Negative로 잘못 판단하게 되면 큰 문제가 되는 경우이다.
F1 스코어
정밀도(Precision)와 재현율(Recall)을 결합한 지표

정밀도와 재현율이 한쪽으로 치우치지 않은 수치를 나타낼 때 상대적으로 높은 값을 가진다.
ROC AUC
이진 분류의 예측 성능 측정에서 중요하게 사용되는 지표

민감도(True Positive Rate)는 실제 값 Positive가 정확히 예측돼야 하는 수준을 나타낸다.
특이성(True Negative Rate)은 실제 값 Negative가 정확히 예측돼야 하는 수준을 나타낸다.
False Positive Rate는 FP / (FP + TN)로 1 - 특이성을 의미한다.
위의 그래프에서 ROC 곡선은 가운데 직선에 가까울수록 성능이 떨어지는 것이고 멀어질수록 성능이 뛰어난 것이다.
출처 : 파이썬 머신러닝 완벽 가이드 (위키북스) - 권철민
'머신러닝' 카테고리의 다른 글
| [머신러닝] 차원 축소(Dimension Reduction) 알고리즘 (0) | 2021.03.28 |
|---|---|
| [머신러닝] 회귀 평가 지표 (0) | 2021.03.27 |
| [머신러닝] 회귀(Regression) 알고리즘 (0) | 2021.03.25 |
| [머신러닝] 분류(Classification) 알고리즘 (1) | 2021.03.18 |
| [머신러닝] 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning) (1) | 2021.03.16 |



